encmistake: Reconstruct the "digital" journey of miscoded texts ‒ Prolog skript
The reason for the creation of the script were those wrongly encoded texts which you occasionally find on the internet and sometimes produce by yourself. They look like this:
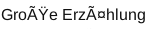
(in words: "Große Erzählung" ‒ "Große Erzählung" would be correct.)
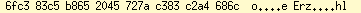
Out of couriosity I wrote a Prolog script which tries all possible ways of
the mistake which could have happened. You can download it here:
Download: encmistake.pl (ca. 20 kB)
Licence and Notice: LICENSE, NOTICE
You can invoke the script like this:
me@supermachine:encmistake$ swipl ./encmistake.pl Welcome to SWI-Prolog (threaded, ...) ?- translate(utf8, "c39f", _, "c383c5b8", D). D = 'utf8 -> [utf8"="cp1252] -> utf8' ; D = 'utf8 -> [utf8"="cp1252] -> utf8' ; false. ?- halt. me@supermachine:encmistake$
So this tells us that the UTF-8 "ß" (= 0xc3 0x9f) was pretty correct, but someone (or some automaton) decided to convert this "CP1252" text to UTF-8.
See here a graph whith the "journey of the string":
original misinterpreted "transformation" result CP1252 => UTF-8 0xc3 0x9f 0xc3 0x9f = 0xc3 0x83 0xc5 0xb8 --------- ---> ---- ---- --------=-------> --------- --------- | | | | | | | "Ÿ" codepoint | "Ÿ" codepoint | | in CP1252 | in UTF-8 "ß" codepoint | | in UTF-8 "Ã" codepoint "Ã" codepoint in CP1252 in UTF-8
See also "Translations" for Latvian and Hungarian letters (external link)