encmistake: die "digitale" Reise von fehlkodierten Texten nachverfolgen ‒ Prolog-Skript
Grund für die Erstellung des Scripts sind die fehlcodierten Texte, die man manchmal im Internet finden kann und manchmal selbst produziert. Sie sehen z. B. so aus:
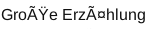
(in Worten: "Große Erzählung" ‒ "Große Erzählung" wäre hier richtig)
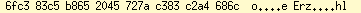
Aus Neugier habe ich ein Prolog-Skript geschrieben, welches die möglichen
Fehlerentstehungswege durchprobiert. Es ist wie folgt zu downloaden:
Download: encmistake.pl (ca. 20 kB)
Lizenz und Lizenzzusatz: LICENSE, NOTICE
Hier ist ein Beispielaufruf:
me@supermachine:encmistake$ swipl ./encmistake.pl Welcome to SWI-Prolog (threaded, ...) ?- translate(utf8, "c39f", _, "c383c5b8", D). D = 'utf8 -> [utf8"="cp1252] -> utf8' ; D = 'utf8 -> [utf8"="cp1252] -> utf8' ; false. ?- halt. me@supermachine:encmistake$
Die Programmaussage bedeutet folgendes: Das UTF-8-Zeichen "ß" (= 0xc3 0x9f) war mal korrekt, aber jemand (oder ein Automat) hat entschieden, diesen "CP1252"-Text nach UTF-8 zu konvertieren.
Im folgenden Graphen wird die "Reise des Strings" deutlich:
Original fehlinter- "Konvertierung" Ergebnis pretiert CP1252 => UTF-8 0xc3 0x9f 0xc3 0x9f = 0xc3 0x83 0xc5 0xb8 --------- ---> ---- ---- -------=-------> --------- --------- | | | | | | | "Ÿ" codepoint | "Ÿ" codepoint | | in CP1252 | in UTF-8 "ß" codepoint | | in UTF-8 "Ã" codepoint "Ã" codepoint in CP1252 in UTF-8
Siehe auch "Übersetzungen" für lettische und ungarische Buchstaben (externer Link auf englisch)